#> +-- batch
#> +-- pip_ingestion_pipeline.Rproj
#> +-- R
#> +-- README.md
#> +-- renv
#> +-- renv.lock
#> +-- run.R
#> +-- _packages.R
#> \-- _targets
#> \-- _targets.R9 Poverty Calculator Pipeline (pre-computed estimations)
The Poverty Calculator Pipeline–hereafter, and only for the rest of this chapter, pipeline–is the technical procedure to calculate the pre-computed (or statitic) estimations of the PIP project. These estimations have two main purposes:
- To provide the user with instantaneous information about distributive measures of all the household surveys in the PIP repository that do not depend on the value of the poverty line (e.g. mean income, quantiles). Avoiding thus the need for re-computation as it was the case in PovcalNet for some of these measures.
- To provide the necessary inputs to the PIP API.
This chapter walks you through the folder structure of the folder, the main R script, _targets.R, and the complete and partial execution of the script. Also, it provides some tips for debugging.
9.1 Folder structure
The pipeline is hosted in the Github repository PIP-Technical-Team/pip_ingestion_pipeline. At the root of the repo you will find a series of files and folders.
Folders
Rcontains long R functions used during the pipelinebatchis a script for timing the execution of the pipeline. This folder should probably be removed_targetsis a folder for all objects created during the pipeline. You don’t need to look inside as its content is managed by thetargetspackage.renvis a folder for reproducible environment.
Files
_packages.Ris created bytargets::tar_renv(). Do not modify manually._targets.Rcontains the pipeline. This is the most important file.
9.2 Prerequisites
Before you start working on the pipeline, you need to make sure to have the following PIP packages.
Note 1: notice that instructions below contain suffixes like
@development. These specify the branch of the particular package that you need to use. Ideally, all packages should use the master branch; however, that will only be possible until the end of the development process.
Note 2: if you update any of the packages developed by the PIP team, make sure you always increased the version of the package using the function
usethis::use_version(). Even if the change in the package is small, you need on increased the version of the package. Otherwise,{targets}won’t execute the sections of the pipeline that run the functions you changed.
remotes::install_github("PIP-Technical-Team/pipdm@development")
remotes::install_github("PIP-Technical-Team/pipload@development")
remotes::install_github("PIP-Technical-Team/wbpip@halfmedian_spl")
install.packages("joyn")In case renv is not working for you, you may need to install all the packages mentioned in the _packages.R script at the root of the folder. Also, make sure to install the most recent version of targets and tarchetypes packages.
9.3 Structure of the _targets.R file
Even thought the pipeline script looks like a regular R script, it is structured in a specific way in order to make it work with the {targets} package. In fact, notice that it must be called _targets.R at the root of the project. It is highly recommended that you read the entire targets manual to fully understand how it works. We will often be referring to such manual in order to expand on any particular targets’ concept.
Start up
The first part of the pipeline sets up the environment. The process involve,
- loading the
{targets}and{tarchetypes}packages;
- creating default values like directories, time stamps, survey and reference years boundaries, compression level of .fst files, etc.;
- executing
tar_option_set()to set up an option in{targets}.packagesandimportsare two particularly important options to track changes in package dependencies. You can read more about it in the sections Loading and configuring R packages and Packages-based invalidation of the targets manual; - attaching all the packages and functions of the project by running
source('_packages.R')andsource('R/_common.R').
Step 1: small functions
According to the section Functions in pipelines of the targets manual, it is recommend to only use functions rather than expressions during the executions. Presumably, the reason for this is that targets track changes in functions but not in expressions. Thus, this scripts section defines small functions that are executed along the pipeline. In the section above, the scripts source('R/_common.R') loads longer functions. Yet, keep in mind that the 'R/_common.R' was used in a previous version of the pipeline before {targets} was implemented. Now, most of the function in 'R/_common.R' are included in the {pipdm} package.
Step 2: preparing the data
This section used to be longer in previous versions of the pipeline because it used to identify the auxiliary data, load the PIP microdata inventory, and create the cache files. It now only identifies the auxiliary data.
Step 3: The actual pipeline
Although better explained in the next section, the overall order of the pipeline is as follows:
Load all necessary data (that is, auxiliary data and inventories), and then create any cache fie that has not been created yet.
Calculate means in LCU
Crate deflated survey mean (DSM) table
Calculate reference year table (aka., interpolated means table)
Calculate distributional stats
Create output tables
join survey mean table with dist table
join reference year table with dist table
coverage table aggregate population at the regional level table
Clean and save.
9.4 Understanding the pipeline
We must understand not only how the {targets} package works, but also how the targets of the Poverty Calculator Pipeline are created. For the former, you can read the targets manual. For the latter, we should start by making a distinction between the different types of targets.
In {targets} terminology, there are two kinds of targets, stems and branches. Stems are unitary targets. That is, for each target there is only one single R object. Branches, on the other hand, are targets that contain several objects or subtargets inside (you can learn more about them in the chapter Dynamic branching of the targets manual). We will see the use of this type of targets when we talk about the use of cache files.
Stem targets
There are two ways to create stem targets: either using tar_target() or using tar_map() from the {tarchetypes} package. The tar_map() function allows to create stem targets iteratively. See for instance the creation of targets for each auxiliary data:
tar_map(
values = aux_tb,
names = "auxname",
# create dynamic name
tar_target(
aux_dir,
auxfiles,
format = "file"
),
tar_target(
aux,
pipload::pip_load_aux(file_to_load = aux_dir,
apply_label = FALSE)
)
)tar_map() takes the values in the data frame aux_tb created in Step 2: preparing the data and creates two type of targets. First, it creates the target aux_dir that contains the paths of the auxiliary files, which are available in the column auxfiles of aux_tb. This is done by creating an internal target within tar_map() and using the argument format = "file". This process lets {targets} know that we will have objects that are loaded from a file and are not created inside the pc pipeline.
Then, tar_map() uses the the column auxname of aux_tb to name the targets that contain the auxiliary files. Each target will be prefixed by the word “aux”. This is why we had to add the argument file_to_load to pipload::pip_load_aux, so we can let {targets} know that the file paths defined in target aux_dir are used to create the targets prefixed with “aux”, which are the actual targets. For example, if I need to use the population data frame inside the pc pipeline, I’d use the target aux_pop, which had a corresponding file path in aux_dir. This way, if the original file referenced in aux_dir changes, all the targets that depend on aux_pop will be run again.
Branches targets
Let’s think of a branch target like…
As explained above, branch targets are targets made of many “subtargets” that follow a particular pattern. Most of the targets created in the pc pipeline are branch targets because we need to execute the same procedure in every cache file. This could have been done internally in a single one, but then we would lose the tracking features of {targets}. Additionally, we could have created a stem target for every cache file, result, and output file, but that would have been both impossible to visualize and more difficult to code. Hence, branch targets is the best option.
The following example illustrates how it works,
# step A
tar_target(
cache_inventory_dir,
cache_inventory_path(),
format = "file"
),
# step B
tar_target(
cache_inventory,
{
x <- fst::read_fst(cache_inventory_dir,
as.data.table = TRUE)
},
),
# step C
tar_target(cache_files,
get_cache_files(cache_inventory)),
# step D
tar_files(cache_dir, cache_files),
# step E
tar_target(cache,
fst::read_fst(path = cache_dir,
as.data.table = TRUE),
pattern = map(cache_dir),
iteration = "list")The code above illustrates several things. It is divided in steps, with the last step (step E) being the part of the code where the branch target is created. Yet, it is important to understand all the previous steps.
In step A we create target cache_inventory_dir, which is merely the file path that contains the cache inventory. Notice that it is returned by a function and not entered directly into the target. Since it is a file path, we need to add the argument format = "file" to let {targets} know that it is input data. In step B we load the cache inventory file into target cache_inventory by providing the target “path” that we created in step A. This file has several columns. One of them contains the file path of every single cache file in the PIP network drive. That single column is extracted from the cache inventory in step C. Then, in step D, each file path is declared as input, using the convenient function tar_files(), creating thus a new target, cache_dir. Finally, we create branch target cache with all the cache files by loading each file. To do this iteratively, we parse the cache_dir target to the path argument of the function fst::read_fst() and to the pattern = map() argument of the tar_target() function. At the very end, we need to specify that the output of the iteration is stored as a list, using the argument iteration = "list".
The basic logic of branch targets is that the vector or list to iterate through should be parsed to the function’s argument and to the pattern = map() argument of the tar_target() function. It is very similar to purrr::map()
Note: if we are iterating through more than one vector or list, you need to (1) separate each of them by commas in the
map()part of the argument (See example code below). (2) make sure all the vectors or lists have the same length. This is why we cannot remove NULL or NA values from any target. (3) make sure you do NOT sort any of the output targets as it will loose its correspondence with other targets.
# Example of creating branch target using several lists to iterate through.
tar_target(
name = dl_dist_stats,
command = db_compute_dist_stats(dt = cache,
mean = dl_mean,
pop = aux_pop,
cache_id = cache_ids),
pattern = map(cache, dl_mean, cache_ids),
iteration = "list"
)Creating the cache files
The following code illustrates the creation of cache files:
tar_target(pipeline_inventory, {
x <- pipdm::db_filter_inventory(
dt = pip_inventory,
pfw_table = aux_pfw)
# Uncomment for specific countries
# x <- x[country_code == 'IDN' & surveyid_year == 2015]
}
),
tar_target(status_cache_files_creation,
pipdm::create_cache_file(
pipeline_inventory = pipeline_inventory,
pip_data_dir = PIP_DATA_DIR,
tool = "PC",
cache_svy_dir = CACHE_SVY_DIR,
compress = FST_COMP_LVL,
force = TRUE,
verbose = FALSE,
cpi_dt = aux_cpi,
ppp_dt = aux_ppp)
)It is important to understand this part of the pc pipeline thoroughly because the cache files used to be created in Step 2: preparing the data rather than here. Now, it has not only been integrated in the pc pipeline, but it is also possible to execute the creation of cache files independently from the rest of the pipeline, by following the instructions in [Executing the _targets.R file].
The first target, pipeline_inventory is just the inner join of the pip inventory dataset and the price framework (pfw) file, to make sure we only include what the pfw says. This data set also contains a lot of useful information to create the cache files. Note that the commented line in this target would filter the pipeline inventory to have only the information for IDN, 2015. If you need to update specific cache files, you must add the proper filtering condition there.
In the second target, status_cache_files_creation, you will create the cache files but notice that the returning value of the function pipdm::create_cache_file() is not the cache file per-se, but a list with the status of the creation process. If the creation of a particular file fails, it does not stop the iteration that creates all the cache files. At the end of the process, it returns a list with the creation status of each cache file. Notice that the function pipdm::create_cache_file() requires the CPI and the PPP auxiliary data. That is because the variable welfare_ppp, which is the welfare aggregate in 2011 PPP values, is added to the cache files. FInally, and more importantly, the argument force = TRUE ensures that even if the cache file already exists, it should be modified. This is important when you require additional features in the cache file from the then ones it currently has. If set to TRUE, it will replace any file in the network drive that is listed in pipeline_inventory. If set to FALSE, only the files that are in pipeline_inventory -but not in the cache folder- will be created. Use this option only when you need to add new features to all cache data, or when you are testing and only need a few surveys with the new features.
9.5 Understanding {pipdm} functions
The {pipdm} package is the backbone of the pc pipeline. It is in charge of executing the functions in {wbpip} and consolidate the new DataBases. This is why many of the functions in {pipdm} are prefixed with “db_”.
9.5.1 Internal structure of {pipdm} functions
The main objective of {pipdm} is to execute the functions in {wbpip} to do the calculations and then build the data frames. As of today (2023-08-24), the process is a little intricate.
Let’s take the example of estimating distributive measures in the pipeline. The image below shows that there are at least three intermediate function levels between the db_compute_dist_stats() function, which is directly executed in the pc pipeline, and the wbpip::md_compute_dist_stats(), which makes the calculations. Also, notice that the functions are very general in regards to the output. No higher level function is specific enough to retrieve only one measure, such as the Gini coefficient, or the median, or the quantiles of the distribution. If you need to add or modify one particular distributive measure, you must do it in functions inside wbpip::md_compute_dist_stats(), making sure the new output does not mess up the execution of any of the intermediate functions before the results get to db_compute_dist_stats().
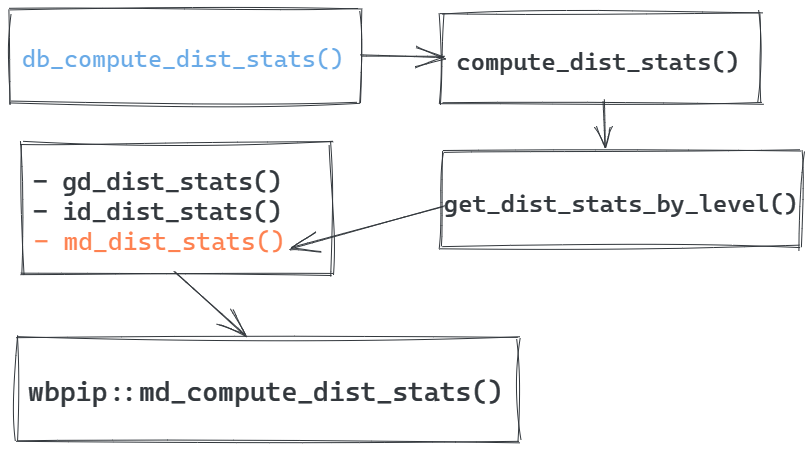
This long chain of functions is inflexible and makes debugging very difficult. So, if you need to make any modification, first identify the chain of execution in each pipdm function you modify, and then make sure your changes do not affect the output format as it may break the execution chain. This is also a good example of why this structure needs to be improved.
9.5.2 Updating {pipdm} (or any other PIP package)
As explained above, if you need to modify any function in pipdm or in wbpip, you need to make sure that the output does not conflict with the execution chain. Additionally, If you update any of the packages developed by the PIP team, make sure you always increased the version of the package using the function usethis::use_version(). Even if the change in the package is small, you need to increase the version of the package. Otherwise, {targets} won’t execute the sections of the pipeline that run the functions you changed. Finally as explained in the Prerequisites, if you are working on a branch different than master, make sure you install that version of the package before running the pipeline.
9.6 Executing the _targets.R file
The .Rprofile at the root of the directory makes sure that both {targets} and {tarchetypes} are loaded when the project is started. The whole pipeline execution might be very time consuming because it still needs to load all the data in the network drive. If you use a desktop remote connection the execution might be faster than running it locally, but it is still very time consuming. So, it is advisable to only execute the targets that are directly affected by your changes and manually check that everything looks ok. After that, you can execute the entire code confidently and leave it running overnight.
In order to execute the whole pipeline, you only need to type the directive tar_make() in the console. If you want to execute only one target, then type the name of the target in the same directive, e.g., tar_make(dl_dist_stats). Keep in mind that if the inputs of prior targets to the objective target have changed, those targets will be executed first.
9.7 Debugging
Debugging in targets is not easy. Yet, there are two ways to do it. The first way is provided in the chapter Debugging of the Targets Manual. It provides clear instruction on how to debug while still being in the pipeline, but it could be the case that you don’t find this method flexible to dig deep enough into the problem. Alternatively, you could debug by stepping out of the pipeline a little bit and gain more flexibility, as described below.
Debugging is needed in one of two cases: one, because you got an error when running the pipeline with tar_make() or, two, because your results are odd. In either case, you should probably have an idea–though not always–of where the problem is. If the problem is an error in the execution of the pipeline, {targets} printed messages are usually informative.
Debugging stem targets
Let’s see a simple example. Assume the problem is in the target dt_dist_stats, which is created by executing the function db_create_dist_table of the {pipdm} package. Since the problem is in there, all the targets and inputs necessary to create dt_dist_stats should be available in the _targets/ data store. So, you can load them using tar_load() and execute the function in debugging mode. Like this,
tar_load(dl_dist_stats)
tar_load(svy_mean_ppp_table)
tar_load(cache_inventory)
debugonce(pipdm::db_create_dist_table)
pipdm::db_create_dist_table(
dl = dl_dist_stats,
dsm_table = svy_mean_ppp_table,
crr_inv = cache_inventory
)Note that you must use the :: because the environment in which {targets} runs is different from your global environment, in which you might not have attached all the libraries.
Debugging branch targets
The challenge debugging branch targets is that if the problem is in a specific survey, you can’t access the “subtarget” using the survey ID, or something of that nature, because the name of the subtarget is created by {targets} using a random number. This requires a little more of work.
Imagine now that the distributive measures of IDN 2015 are wrong. You see the pipeline and notice that these calculations are executed in target dl_dist_stats, which is the branch target created over all the cache files! It would look like something like this:
tar_target(
name = dl_dist_stats,
command = db_compute_dist_stats(dt = cache,
mean = dl_mean,
pop = aux_pop,
cache_id = cache_ids),
pattern = map(cache, dl_mean, cache_ids),
iteration = "list"
)In order to find the problem in IDN 2015, this what you could do:
# Load data
dt <- pipload::pip_load_cache("IDN", 2015, "PC")
tar_load(dl_mean)
tar_load(cache_ids)
tar_load(aux_pop)
# Extract corresponding mean and cache ID
idt <- which(cache_ids == unique(dt$cache_id))
cache_id <- cache_ids[idt]
mean_i <- dl_mean[[idt]]
# Esecute the function of interest
debugonce(pipdm:::compute_dist_stats)
ds <- pipdm::db_compute_dist_stats(dt = dt,
mean = mean_i,
pop = aux_pop,
cache_id = cache_id)First, you load all the inputs. Since target dl_mean is a relatively light object, we load it directly from the _targets/ data store. Targets cache_ids and aux_pop are data frames, not lists, so we also load them from memory. The microdata, however, is problematic because target cache, which is the one that is parsed to create the actual dl_dist_stata target, is a huge list with all the micro, grouped, and imputed data. The solution is then to load the data frame of interest, using either pipload or fst.
Secondly, we need to filter the list dl_mean and the data frame cache_ids to parse only the information accepted by the pipdm::db_compute_dist_stats() function. This has to be done when debugging because in the actual target this is done iteratively in pattern = map(cache, dl_mean, cache_ids).
Finally, you execute the function of interest. Notice something else. The target aux_pop is parsed as a single data frame because pipdm::db_compute_dist_stats() requires it that way. This is also one of the reasons why these functions in {pipdm} need some fixing and consistency in the format of the their inputs.